將 MongoDB 資料庫由一組 Shard 組成並且各 Shard 分散在不同機器儲存, 以 水平 的方式將資料擴展,並可隨著需求即時 新增 或 刪除 Shard。
優勢:
- 有效降低
讀/寫的工作負載
將整個資料庫分成多個 shards,將讀寫操作分散在不同機器上,有效降低單一機器負載。
- 提升
存儲容量,可隨著資料的增長,橫向擴展增加 Shard 的數量
可將存儲資料分成各個 Shard 並分散於不同的機器,有效提升整體存儲容量
- 可搭配使用 Replica Set,提升
可用性
將分散於在不同機器的 Shard 搭配使用 Replica Set 架構,當某個 Shard 不可用時,就會由Secondary 節點替代,達到
可用性。
劣勢
- 架構設計較為複雜
實現架構時,需要在較多的機器建立實體以及配置設定檔
- 延遲較多
可能需在各個 Shard 中進行資料操作並回傳,耗時將比單機架構多
存儲方式
選定一個欄位做為 Shard Key 以及將此 Shard Key 去分群,以下是 MongoDB 兩種不同的分群機制:
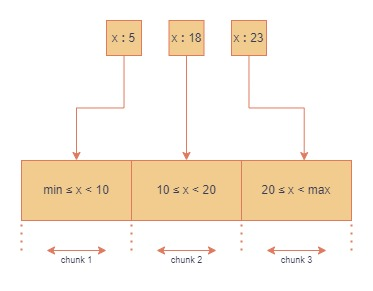
Range Based Partitioning
以線性的方式分群,相近範圍的資料會被分在同一個 Chunk,好處是 Router 可以很輕易的判斷分布在哪個 Shard,Query 較快,但如果資料 Range 都相近,那麼特定 Chunk 的資料量會特別大,且整體分布也不平均,可能會造成某個 Shard 讀/取負擔過大。
運作如下:
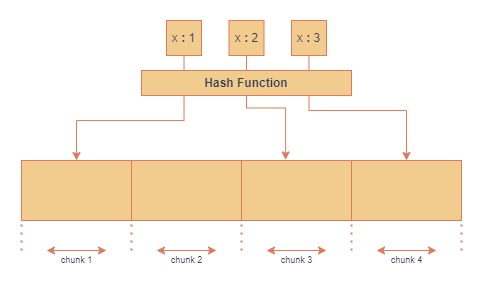
Hash Based Sharding
透過 雜湊函式 將 Shard Key 分配到各個 Chunk,好處是用此方式資料分散性比較 平均,但進行範圍查詢時,就需要到各個 Shard 獲取資料,查詢耗時可能較長。
運作如下:
基本成員
儲存資料的節點,每個 Shard 都是整體資料的
子集。
Router(mongos)
做為整個 Sharded Cluster 的訪問入口,所有請求都由 mongos 路由、分發、合併。
- 讀取請求
條件不包含Shard Key:將會將請求發送到整個 Shards,合併查詢結果回傳
條件包含Shard Key:將根據 Shard Key 計算出位於哪個 Chunk,再向對應的 Shard 發出查詢 - 寫入請求
根據分群機制算出 Shard Key 應存在哪個 Chunk,再寫入該 Chunk 所在的 Shard - 更新/刪除請求
若條件有包含到 Shard Key 則直接路由到該 Chunk 執行,否則將請求發送到整個 Shards
Config Servers
紀錄了每一筆資料(doc)存放的 Chunk 位置,以及哪些 Shard 存儲了哪些 Chunk,也是 Balancer 均衡器運行的所在位置。
- Chunk
分片的 Metadata,預設為 64 MB,可調整大小(chunkSize)- ChunkSize 很小:分裂及遷移的情況較多,資料越均衡,但容易造成 Jumbo Chunk(例如:出現很多相同 Shard Key,就會聚集在同一個 Chunk)
- ChunkSize 很大:分裂及遷移的情況較少,資料可能不均衡
- Balancer
位在 Config Server 的一個背景程序(預設會開啟),主要是監控每一個 Shard 內的 Chunks 差異量,如果超過定義的差異量(Migration Thresholds),Balancer 會在約束條件(EX: Range 分區)下自動執行moveChunk指令在分片之間進行遷移,使每個 Shard 的 Chunks 達到均衡,而當擴展與刪除Shard 的過程中也會進行平衡。
基本架構
Query Work Flow
- 透過 Mongos(Router) 接收外部請求
- Mongos(Router) 會請 Config Servers 根據 Shard Key 找出請求資料 Shard 所在位置或是發送請求到各個 Shard
- Mongos(Router) 便可以正確找到各個資料對應的 Shard,於查詢後再合併資料
- 回傳結果給 User

參考
MongoDB Sharding 分散式儲存架構建置 (概念篇)
為什麼要用 Docker?如何用 Docker 構築不同 MongoDB 架構?
純乾貨|一文看懂 資料庫分片(Database Sharding)詳解